

Scenario planning dominates enterprise risk management. It also fails, structurally and repeatedly, for exactly the kind of risks that threaten global companies most. This article explains why, and what resilience-based systems analysis does instead.
On February 1, 1997, a fire broke out at the Aisin Seiki factory in Kariya, Japan. Aisin was the sole supplier of a specific brake component to Toyota, and its JIT inventory meant Toyota carried roughly two days of stock. Analysts predicted a disruption of weeks, possibly months. Production resumed in five days.
What made the recovery possible was not a contingency plan, and it was certainly not a scenario document. It was the structural properties of Toyota's supplier network: the trust, the technical transparency, the modularity of manufacturing capability that allowed 200 firms to self-organize an improvised production system over a single weekend. No one at Toyota had planned for a fire at that exact facility. They had built something more durable than a plan.
This is the core distinction that most enterprise risk frameworks never quite make. There is a meaningful difference between preparing for what you think will happen and building the structural capacity to absorb and recover from whatever does happen. The first is scenario planning. The second is resilience-based systems analysis.
The first is where almost all formal risk management investment currently goes. The second is where the survival-critical work actually is.
Why Scenario Planning Dominates, and Why That's a Problem

Scenario planning has proven its worth. It forces long-horizon thinking, surfaces assumptions that normally go unexamined, and creates a shared organizational vocabulary for discussing uncertainty. The Royal Dutch/Shell work of the 1970s, which let the company outperform peers through two oil shocks precisely because it had thought through discontinuous futures, is a legitimate piece of intellectual history.
The problem is not that scenario planning is useless. The problem is that it has been institutionalized far beyond what its underlying logic can support.
The core assumption of scenario planning is that the future can be scoped: you can identify the key uncertainties, construct meaningful combinations of how they might resolve, and prepare for those combinations.
Philip Tetlock spent twenty years studying roughly three hundred expert forecasters making thousands of predictions, and what he found in Expert Political Judgment was that the foundation of this approach is weaker than almost anyone in the field acknowledges.
Expert forecasters performed at near-chance levels for anything beyond eighteen months, and the worst-performing forecasters were not the uninformed ones; they were the experts with the most internally consistent, confidently structured mental models.
The more rigorous the scenario process, the more confidently it excludes the actual risk. And the more it is, statistically, wrong.
This is not just an academic observation. The 2008 financial crisis produced the clearest empirical demonstration. Every major global bank operated sophisticated quantitative risk models, "Value at Risk" frameworks that used historical price distributions to estimate maximum losses across a range of scenarios.
These models shared a structural assumption: that asset correlations were stable, that tail events followed historical distributions, and that individual institutions' risks were separable enough to be managed independently.
What the models did not represent was systemic contagion: where correlated failures cascade across interdependent institutions simultaneously.
When Lehman Brothers failed, it held complex products across more than 3,000 legal entities worldwide. The cascade that followed was not anywhere in scope of any planned scenario. It was an emergent property of structural interdependencies that no scenario analysis had mapped.
Nassim Taleb had published The Black Swan the previous year, arguing that "the most dangerous risks do not reside in the same mental model as the expected." He was correct, and the banks' own scenario processes had made this inevitable.

What Complex Systems Actually Do

The deeper issue is not that scenario planners are insufficiently skilled. It is that scenario planning is a complicated-domain tool applied to complex-domain problems. Dave Snowden and Mary Boone introduced this distinction in a 2007 Harvard Business Review article through the Cynefin framework, and it is operationally precise in a way that most risk discussions are not.
SiD also recognizes the fundamental difference between the two operative words here: complicated versus complex. One is knowable (consisting of finite elements). The other is not (infinite and non-linear).
Donna Meadows put this precisely in Thinking in Systems: "the behavior of a system cannot be predicted simply by examining its components." This is not a philosophical caution; it is an engineering constraint. It can not be defeated by brain or computing power.
The semiconductor shortage that cascaded through global manufacturing in 2021 was not caused by any single failure. It emerged from the interaction of pandemic-driven demand surges, decades of geographic concentration in chip fabrication, just-in-time inventory practices that eliminated buffer, and geopolitical fragmentation that prevented coordinated response. Each element alone was manageable by some scenario process. Their correlated interaction was a structural property of the global supply system, not a predictable scenario.
Complicated systems, like an aircraft or a supply chain contract, are knowable with sufficient expertise: cause and effect are traceable, best practices exist, analysis is sufficient.
Complex systems, like a multinational supply network, a financial market, or an ecological habitat, behave differently. Cause and effect can only be understood in retrospect. Emergent behaviors arise from the interactions of components in ways that cannot be predicted by analyzing those components individually.
Nancy Leveson's accident model STAMP, introduced in a 2004 paper in Safety Science, formalizes what this means for organizations. Accidents in complex systems, Leveson argues, are almost never caused by any sequence of events that anyone had modeled. They are caused by emergent behaviors in a system's control structure that the organization's safety architecture was never built to handle.
The Boeing 737 MAX is the textbook illustration. Boeing's engineers ran extensive scenario analyses for the aircraft's certification. What no scenario captured was the interaction between four seemingly distinct areas: 1) financial pressure to match Airbus without a retraining certification. 2) the organizational culture that had shifted safety escalation into a secondary concern. 3) the decision to not disclose the MCAS flight control software to airlines or pilots. 4)and the engineering choice to rely on a single sensor for a system that could override trained pilots.
Each element existed somewhere in Boeing's organizational architecture. The combination was an emergent property of that architecture's structural degradation, and it killed 346 people across two crashes before the fleet was grounded for twenty months.
A Senate investigation later found "a culture in which schedule and cost pressures discouraged safety escalation." That is a structural description of a broken control loop, visible in Boeing's governance architecture long before the Lion Air and Ethiopian Airlines crashes. No scenario touched it. A systemic resilience analysis would have.

What Resilience-Based Systems Analysis Does Differently

The question that resilience-based analysis asks is structurally different from the one scenario planning asks. Scenario planning asks: what will happen, and are we prepared for it? Resilience analysis asks: what is the structural capacity of this organization to absorb disruption, adapt, and recover regardless of what that disruption is? The shift sounds modest. In practice it changes almost everything about the process of risk management: how you frame the challenge, what you analyze, what you invest in, and what your board-level risk reporting looks like.
Erik Hollnagel, David Woods, and Nancy Leveson formalized the foundations of this approach in Resilience Engineering: Concepts and Precepts in 2006, identifying four organizational capacities that define a resilient system:
- the ability to anticipate likely threats,
- the ability to monitor what is actually happening,
- the ability to respond when things change,
- and the ability to learn from what happened.
None of these capacities are scenario-specific. They are universal, and they are structural: either your organization has built them or it has not. The good thing is, that is a fact about your organization's architecture that can be assessed, measured, and improved without reference to any particular future.
Brian Walker and David Salt, drawing on C.S. Holling's adaptive cycle work, identified three structural properties that make systems resilient in Resilience Thinking:
- redundancy (backup capacity that activates when primary capacity fails),
- modularity (the ability to contain and isolate failures rather than propagate them),
- and diversity (multiple pathways to the same outcome that prevent single-point failure).
These are not aspirational concepts. They are engineering parameters that can be measured: what percentage of your critical inputs are single-source? How clustered are the dependencies in your supply network? How many distinct geographic and technological pathways exist for your key production processes?
Yet, I don't believe resilience is something that can genuinely be "measured" in a fixed framework or formula.
Karl Weick and Kathleen Sutcliffe's work on High Reliability Organizations, documented in Managing the Unexpected, adds the organizational dimension: the companies that perform best under hazardous conditions are not the ones that predicted more of what would go wrong. They are:
- the ones that built cultures of preoccupation with failure,
- reluctance to simplify,
- sensitivity to operational reality,
- and deference to expertise over hierarchy when conditions shift.
None of these are scenario-planning outputs. They are organizational design choices.

The Evidence from Practice

Toyota's post-1997 trajectory is worth following in detail, because it shows both the power of structural resilience and what happens when that power is tested at larger scale.
The 1997 Aisin recovery was not engineered in the moment; it emerged from structural properties Toyota had built over decades. The trust between Toyota and its supplier network, the technical transparency that allowed those suppliers to understand each other's manufacturing capabilities, the modularity that made it possible to redistribute production rapidly: these were outcomes of organizational design choices, not contingency planning.
The 2011 Tohoku earthquake hit a larger and more geographically distributed system, and Toyota's production fell 78% year-over-year in April 2011. Recovery took three months rather than five days. But Toyota drew explicit structural lessons:
it built the RESCUE system, a supply chain database tracking 6,800 components across supplier tiers;
it shifted from pure just-in-time to a hybrid model requiring one to six months of critical component inventory;
it implemented multi-sourcing for strategically significant components.
These were not scenario responses. They were structural redesigns of the supply system itself. When the global semiconductor shortage hit the automotive industry in 2021, Toyota was among the automakers least affected, and the company directly credited its 2011 structural redesign.
The COVID-19 supply chain disruptions illustrate the same pattern at global scale. Many large companies had pandemic scenarios, particularly after SARS in 2003 and H1N1 in 2009. What the scenarios did not capture was the simultaneity: a pandemic that struck at exactly the moment when global supply chains had been optimized to minimal redundancy, just-in-time inventory had eliminated all buffer, logistics infrastructure was operating at maximum utilization, and geopolitical fragmentation prevented coordinated response.
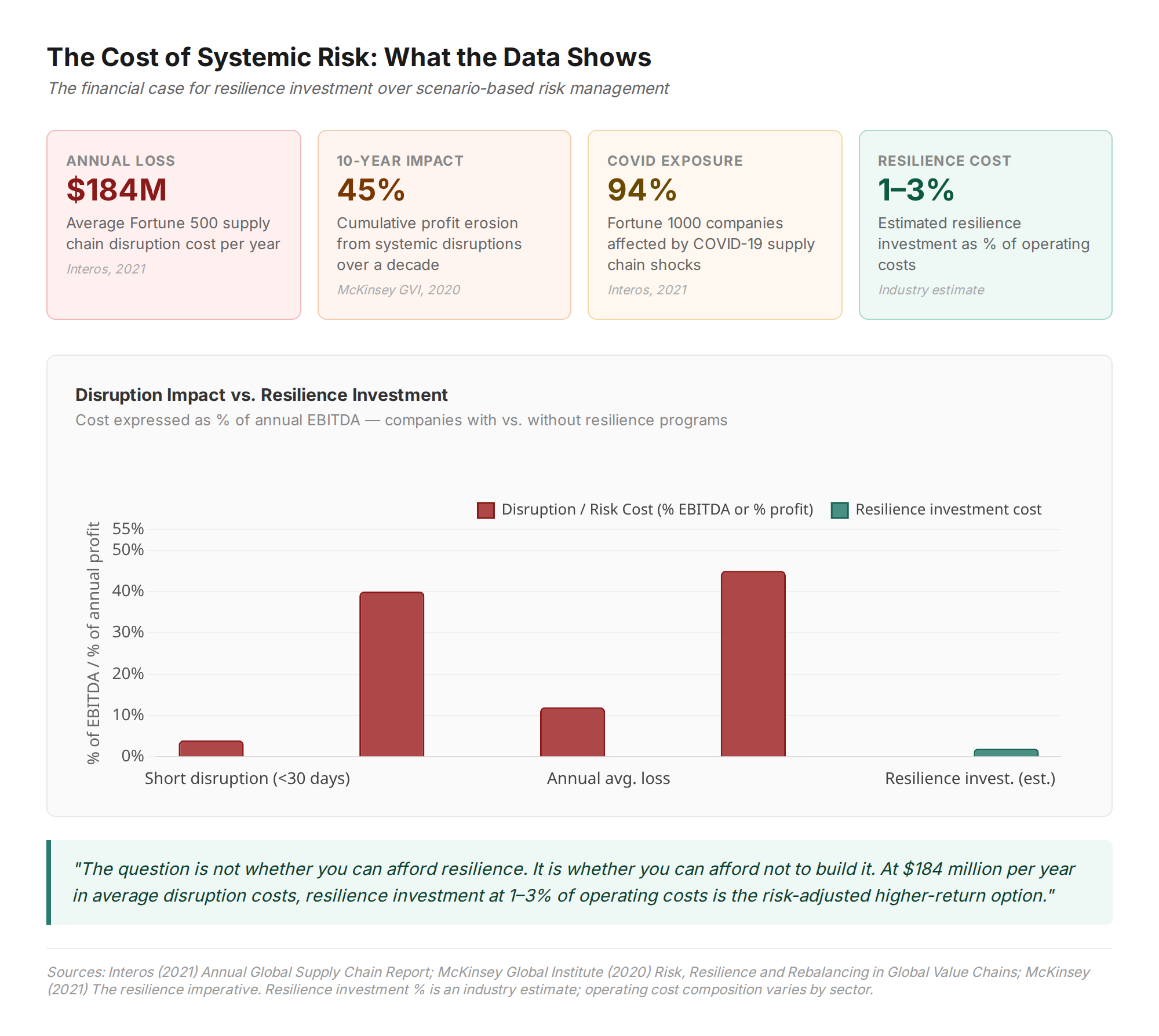
McKinsey estimated in its 2020 Risk, Resilience, and Rebalancing report that the average enterprise had lost over $200 million per year to supply chain disruptions in the preceding decade, with cumulative disruption costs across a ten-year period typically reaching around 45% of a single year's profits.
According to Interos's 2021 research, the average annual cost of supply chain disruptions for a large enterprise was $184 million. Ninety-four percent of Fortune 1000 companies reported supply chain shocks from COVID-19, and most had no adequate structural response.
The companies that fared better were, consistently, the ones that had invested in supply chain mapping across multiple tiers, supplier diversification, and buffer inventory: investments that looked expensive in normal operating conditions and that proved to be the difference between recovery and permanent market share loss.
The Shift in Questions to Ask

The practical implication for C-suite risk governance is a change in what gets measured and what gets reported to boards. Current enterprise risk practice is dominated by probability-impact matrices, risk registers, and scenario probability estimates. These are not wrong, exactly, but they are structurally incomplete: they create a sense of quantitative rigor while systematically underweighing the risks that are structurally invisible to scenario methods, which tend to be precisely the risks that most threaten organizational survival.
Resilience analysis offer a structurally different kind of information. Adaptive capacity indices how quickly and effectively an organization can reorganize under stress, drawing on past disruption recovery performance. Modularity regards, derived from dependency graph analysis, analyzes how contained a failure in one part of the system would be before it propagates to others. Redundancy identifies what percentage of critical inputs, processes, and relationships have genuine backup capacity.

SiD gives a starting set of 9 parameters to start learning to see how a system may behave and exhibit resilience, among others. It's not a formula to calculate. It's lenses to see through, learn, and build an understand that underpins a systemic strategy with the notion of resilience at its core.
Feedback loop mapping shows how long it takes from a signal in operations to a decision in leadership, and where those loops are broken or siloed.
Recovery time objectives, which most organizations think of only in terms of IT disaster recovery, apply just as well to supply chain, regulatory, and reputational disruptions. None of these lenses require predicting the future. They describe the structural state of the present.
Taleb's framework in Antifragile adds the further distinction between organizations that are merely robust (they survive disruptions largely unchanged) and those that are genuinely antifragile (they become structurally stronger from them).
Toyota's trajectory from 1997 to 2021 is an illustration of organizational antifragility: each major disruption was converted into a structural redesign that increased resilience for the next one. That is not an accident. It is the output of an organization that had built Hollnagel's four abilities into its operating culture.
What Integrated Systems Work Looks Like

For organizations that want to move in this direction, the practical challenge is not conceptual. Most C-suite leaders who read Meadows, Hollnagel, or Taleb find the logic compelling. The challenge is methodological: how do you actually map structural resilience across a complex multinational organization, in a way that is rigorous enough to guide investment decisions and specific enough to change governance design?
This is where the gap between theory and practice in most risk functions sits. Scenario planning has well-established professional protocols, industry frameworks, and consulting methodologies. Resilience-based systems analysis does not yet have an equivalent organizational infrastructure in most enterprises, despite the fact that the academic and operational foundations are solid and the Toyota case study is now almost thirty years old.
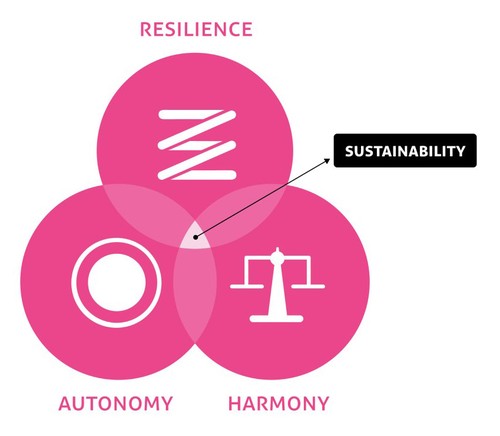
Except's SiD framework approaches this through structural mapping of systems across three systemic areas: Resilience, Autonomy and Harmony. These are fed by network parameters that help scope out the systemic analysis wiring.
The data is subsequently categorized and fed bottom-up through eight integrated dimensions, the ELSI8 categorization that organizes causal dependencies from environmental and living systems foundations through social and institutional layers to economic and technological manifestations.
This architectural design for systemic analysis matters. Risks assessed only in an economic or operational dimension appear manageable until you trace their dependence on system layers where structural fragilities that no scenario process would surface often reside.
The result is not a scenario document. It is a map of structural dependencies and adaptive capacities, and a roadmap to help optimize them. These are oriented toward the specific question of where resilience is lacking, redundancy is absent, where modularity has been optimized away, where feedback loops are broken, and what investments would actually change the organization's recovery trajectory. In social, economic, environmental, and physical dimensions.
The question is not whether complex systems will produce surprises that outrun your scenarios. They will; the evidence on this point is not ambiguous. The question is whether your organization has built the toolkit to develop the resilience for what happens next.
---

May 27, 2026
Further reading

knowledge
Circularity is not sustainability
For a sustainable future, we will need to adopt and develop circularity across every industry and sector. Not only will it …

knowledge
The Anatomy of a System
The term “sustainable” is now ubiquitous across society, yet its actual meaning is elusive and often misunderstood. For exa…

knowledge
The Rise of Systemic Investments
To realize a sustainable society, we need to address our bruised environmental and economic systems in their entirety. For …